The Interesting Economics of Headless Video

The trend to create short videos for Tiktok and Instagram in a fully automated way is fuelled by the very low costs of AI model APIs and the possibility of effort free social media riches. How does it work?
'Headless video' is an online trend where you set up workflows in N8N or Make to generate video content in a fully automated way. Running these workflows on auto allows you to generate a continuous stream of new video content into social media, which accrues views and in theory allows for entry into the monetization programs which reward creators for views and engagement.
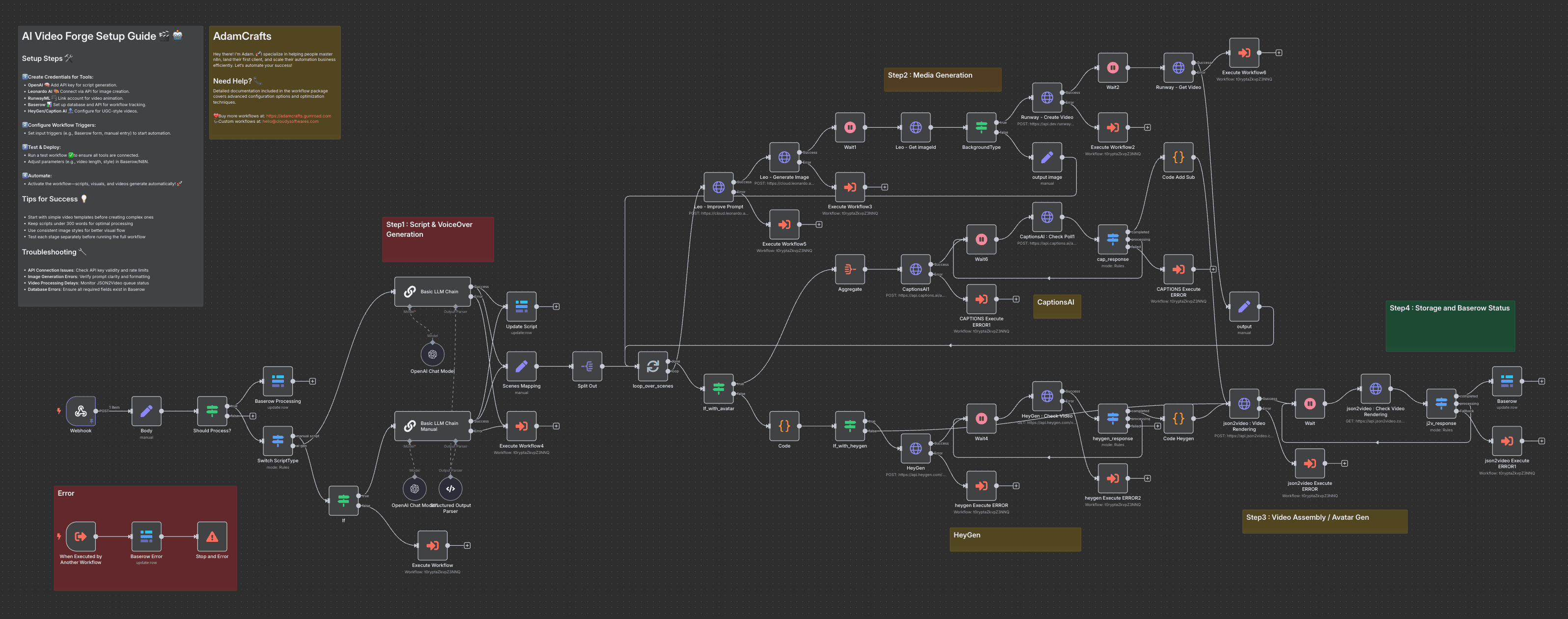
To understand in detail how this works I re-created a video producing workflow as an MVP 'human in the loop' prototype application. This allowed me to experiment with different use cases and explore the economics of implementing them.

Every headless video workflow has five or six main steps. These are:
1. Generate a Script
2. Generate a Voiceover
3. Generate Images
4. Animate one or more images to create short video clips, or generate a short video clip directly
5. optional, not everyone does this: generate overlays
6. Assemble the assets into a completed video
The order of these steps may vary depending on your use case, but generally all of these needs must be satisfied to create a finished asset.
Script Generation
Script Generation is a bit of a misnomer. It is not a video script with scene and character etc.... you are generating a voice over script, the words the narrator will say when you create the voice over. To generate the script you are going to use an LLM. To get access to the LLMs it is a good idea to get an account at OpenRouter.
Openrouter allows you to make API calls to specific models using a common API, allowing you to determine programmatically which model to use. For any specific model OpenRouter may route the request to one of many hosting providers, avoiding downtime and allowing for cost and other optimizations. For text models using Openrouter is a best practice.

I implemented an atomic (does one thing well) script generation workflow in N8n. It calls one model to research the provided topic and write a comprehensive essay about it, then passes that to a different model which boils it down to a small set of words that would take roughly 30 seconds to speak. The prompting for each of these steps is important: it took me a while to get it right, but once that was dialed in I was surprised by how insightful the scripts were across a wide variety of topics.
To run that script, I consumed:
- an N8N workflow consumption charge. N8N charges a starter plan of $25 for 2,500 workflow runs per month, or 1 cent each.
- Open router billed me by token between $0.01 and $0.02 cents for the combined token use to research and then write the script that was produced.
Voiceover Generation
Generating voiceovers utilizes another provider, Eleven Labs. ElevenLabs for $11 per month will provide about 100 minutes of voice generation from text via API. In small round numbers that means a 30 second voice over is worth about $0.05 cents.
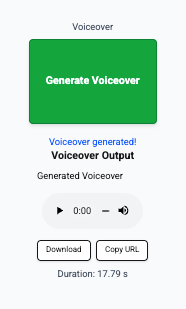
I could go on about Eleven Labs and what they offer: it is well worth an extended exploration of their web site and API, but that is an essay for another day. I will limit the discussion here to say that via API more than 50 different voices can be immediately selected from and some of them are instantly recognizable as standard voiceover actors for all sorts of media. I also implemented voice over generation via Eleven Labs as an atomic N8N workflow, so that adds another $0.01 cent for workflow execution.
Generate Images
Image generation is the core activity of headless video generation. If you have a 30 second voiceover for your video, you need something for people to look at for that amount of time. A general rule I have seen is that each image should remain on screen for no more than 5 seconds: that means for a 30 second video you need to generate six images.
GenZ advisors tell me that AI generated images are less engaging than found media for this type of thing, but it is popular to use them in the pursuit of automation and efficiency. Especially if people are not in the loop and human search and judgement are not available, automated image generation is the obvious strategy to use to create the needed assets.
FAL.ai is the obvious place to go to access the models needed for image generation. Where Openrouter is the primary aggregator for text models for essay writing and chatbots, FAL.ai aggregates image and video models for a large set of categories of use, including text to image, text to video, and image to video, as well as a plethora of other use cases.
Cost / quality tradeoffs are present in these models. The goal is to spend a minimal amount necessary to generate six relevant images of good enough quality. The cost range per image is pretty literally $0.01 cent to $10.00 or more. I tend to use fal-ai/imagen4/preview as a default: it costs $0.04 cents for each image generated and the quality is acceptable enough to not feel too much like AI slop. If there is an issue there are several other alternative models in the same cost range that one can use simply by changing the model identifier in the API call.

If you are using the FAL.ai API directly you can generate multiple images at one time but I found in N8N this tended to generate payload sizes that caused memory issues in the default instance size, so I implemented orchestration to call the atomic N8N workflow once per image. So for six images, add an additional cent per image or $0.06 in total for image workflow calls.
Animate one or more images
I learned this trick from Sabrina at blotato.com. Blotato is a platform that you can use to automate headless video creation and posting and provides several N8N and Make templates you can download and use.
A strategy I observed Blotato uses is to generate images for the post and then animate only the first image in the playlist. The motion of the initially visible asset generates higher engagement, but controls costs. Animating an image into a 5 second video can cost from $0.11 cents for Framepack, which is very meh, to $2.50 for Veo3, the latest (at this writing) Google model. My go-to is fal-ai/bytedance/seedance/v1/lite/image-to-video, which costs $0.18 cents for a five second 720P animation with what I consider baseline acceptable quality.
You can see how costs can pile up here: spending $0.18 cents on an opening video hit can quickly expand to a $1.08 cost if you animated all the images you generated. Using Kling at $2.50 each can turn a $1 investment into a $15 investment. Best to be really cautious here if you are cost conscious at all.
So why not just generate video directly from text like you do the graphics? Obviously you can: the choice seem to be one of risk mitigation. Each video costs as much per second as a single image. By generating images first, you can select the image to be animated and have a sense of the outcome where generating video from text directly is a bit of a game of roulette. You have to pay for the entire video whether you like to enough to use it or not, and you have to commit that sight unseen. Maybe just a little better to get a peek before you commit.
So for a single animated image I would spend $0.18 cents, plus a $0.01 cent N8N workflow fee if I were generating that atomically.
Generate Overlays
I'm going to pretty much skip this. If you want graphics for your posts with your logo or other items then you generate those somehow and make them available for inclusion in the final product. There is no incremental direct cost for this in terms of the video generation itself, its just a choice you can make if it is appropriate.
Assemble the Assets
Now that we have a voiceover, a bunch or graphics, and an animation we can use for an opening asset, we need to assemble all of this into an actual finished video.
The goto site for this is JSON2Video.com. My suspicion is this is somehow a hosted version of VLC, but I have not validated that. JSON2Video does what it is named: you give it JSON describing the video you want and it will assemble the assets and give you back a well formed video file. You can purchase credits on an ad hoc basis that work out to about $0.007 cents per second of video assembled, rated on the final output and varying by resolution.
The only PITA in using JSON2Video is that you do not send the assets directly via API call. Instead you have to mount then somewhere accessible and then pass the URL for each asset as part of the submitted JSON. So you need to set up ephemeral hosting and incur costs for each asset uploaded, accessed, and then deleted as part of your workflow.
Just to close the loop, it is part of the JSON2Video functionality that you can pass overlay graphics or text keys and specify their visibility and layering like any other kind of asset. You can also specify captioning so it is very compelling and visible, which you can see I do.
It is absolutely possible to do all this using N8N but I chose to orchestrate directly just for flexibility as I was trying different things.
So for the 30 second video, add another ~$0.20 cents to the cost base.
Posting
It needs to be mentioned that you can also automate posting to social media services. I did not implement this and so did a minimum of exploration, but of course it can be done for a very small cost and might make sense in a fully automated or volume production environment.
Cost per Finished Asset
Revisiting the list of items, we can assemble a full cost per typical 30 second finished asset as:
1. Generate a Script: $0.03 cents
2. Generate a Voiceover: $0.06 cents
3. Generate Images: $0.30 cents
4. Animate one or more images to create short video clips, or generate a short video clip directly: $0.18 cents
5. optional, not everyone does this: generate overlays: $0.00
6. Assemble the assets into a completed video: $0.20 cents
Total Cost: ~$0.77 cents per 30 second asset
What Next?
Success on social media can be a numbers game. I used my implementation to generate a number of videos based on books in Project Gutenberg.
I could see in the Youtube and Instagram play numbers the algorithm testing those videos to see if they had any viral potential. If they did perform, a positive feedback loop would drive views and engagement to the point where monetization could occur. For content types where this occurs, low cost injection can drive pretty significant ROI.
That did not happen for me, at least so far. So the question is how much more of an investment to make in that content type, or exploring other possible content types. For me at least, its just not clear if I should continue, but it is clear I could at this point produce programmatically and pretty inexpensively just about any social media content I wanted.
It has to be said however that this is sort of like gold mining: its less likely miners strike gold than that they need to buy shovels. The real $ in this game appears to be flowing to providers of model access and video assembly services, who have priced their offerings so cheaply there is (almost) literally no monetary barrier to use.
That low pricing undoubtedly drives a lot of 'get rich quick' driven thinking. In the world of headless video, the shovels are literally flying out the door.